I am a researcher at the FBK NLP in Trento, Italy. This Fall, I will start my PhD at the Bethge Lab in Tübingen, Germany, as an ELLIS PhD Student and as part of the International Max Planck Research School for Intelligent Systems (IMPRS-IS). I also work with Tom Silver’s group for robotics and planning in Princeton, US. Previously, I obtained my MSc degree in Machine Learning, Data Science and Artificial Intelligence from Aalto University in Helsinki, Finland.
I am interested in developing autonomous AI agents that learn from experience and adapt dynamically to new situations. For this, my research is at the intersection of large-scale vision and language models, reinforcement learning, and planning. In particular, I believe world modeling to be a key component for building intelligent agents that can reason about the world and plan their actions accordingly. I work with both simulated games and real-world robotics as environments for agents to learn and adapt in. I am also curious about the connections between AI and cognitive science, and how insights from human cognition can inform the development of more intelligent agents.
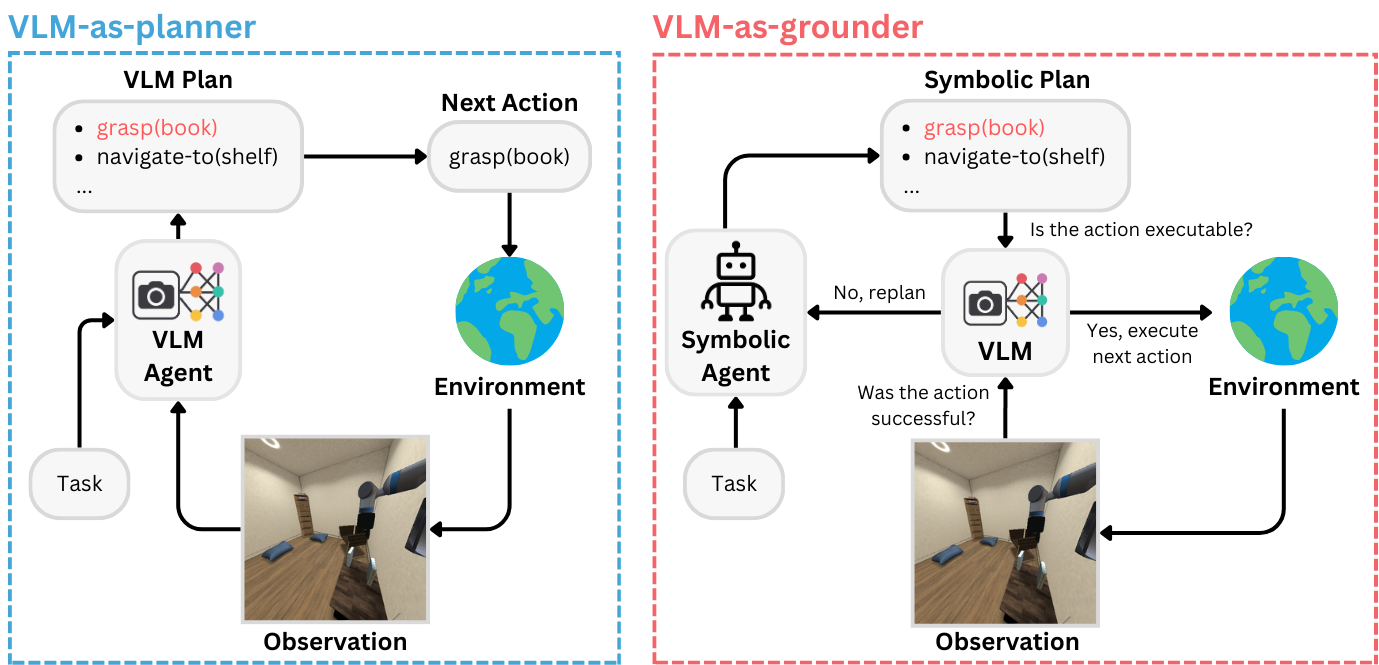
Integrating Large Language Models with symbolic planners is a promising direction for obtaining verifiable and grounded plans compared to planning in natural language, with recent works extending this idea to visual domains using Vision-Language Models (VLMs). However, rigorous comparison between VLM-grounded symbolic approaches and methods that plan directly with a VLM has been hindered by a lack of common environments, evaluation protocols and model coverage. We introduce ViPlan, the first open-source benchmark for Visual Planning with symbolic predicates and VLMs. ViPlan features a series of increasingly challenging tasks in two domains: a visual variant of the classic Blocksworld planning problem and a simulated household robotics environment. We benchmark nine open-source VLM families across multiple sizes, along with selected closed models, evaluating both VLM-grounded symbolic planning and using the models directly to propose actions. We find symbolic planning to outperform direct VLM planning in Blocksworld, where accurate image grounding is crucial, whereas the opposite is true in the household robotics tasks, where commonsense knowledge and the ability to recover from errors are beneficial. Finally, we show that across most models and methods, there is no significant benefit to using Chain-of-Thought prompting, suggesting that current VLMs still struggle with visual reasoning.
@misc{merler2025viplan,title={ViPlan: A Benchmark for Visual Planning with Symbolic Predicates and Vision-Language Models},author={Merler, Matteo and Dainese, Nicola and Alakuijala, Minttu and Bonetta, Giovanni and Ferrazzi, Pietro and Tian, Yu and Magnini, Bernardo and Marttinen, Pekka},year={2025},month=may,cv_date={2025-05-19},eprint={2505.13180},archiveprefix={arXiv},primaryclass={cs.AI},url={https://arxiv.org/abs/2505.13180},}
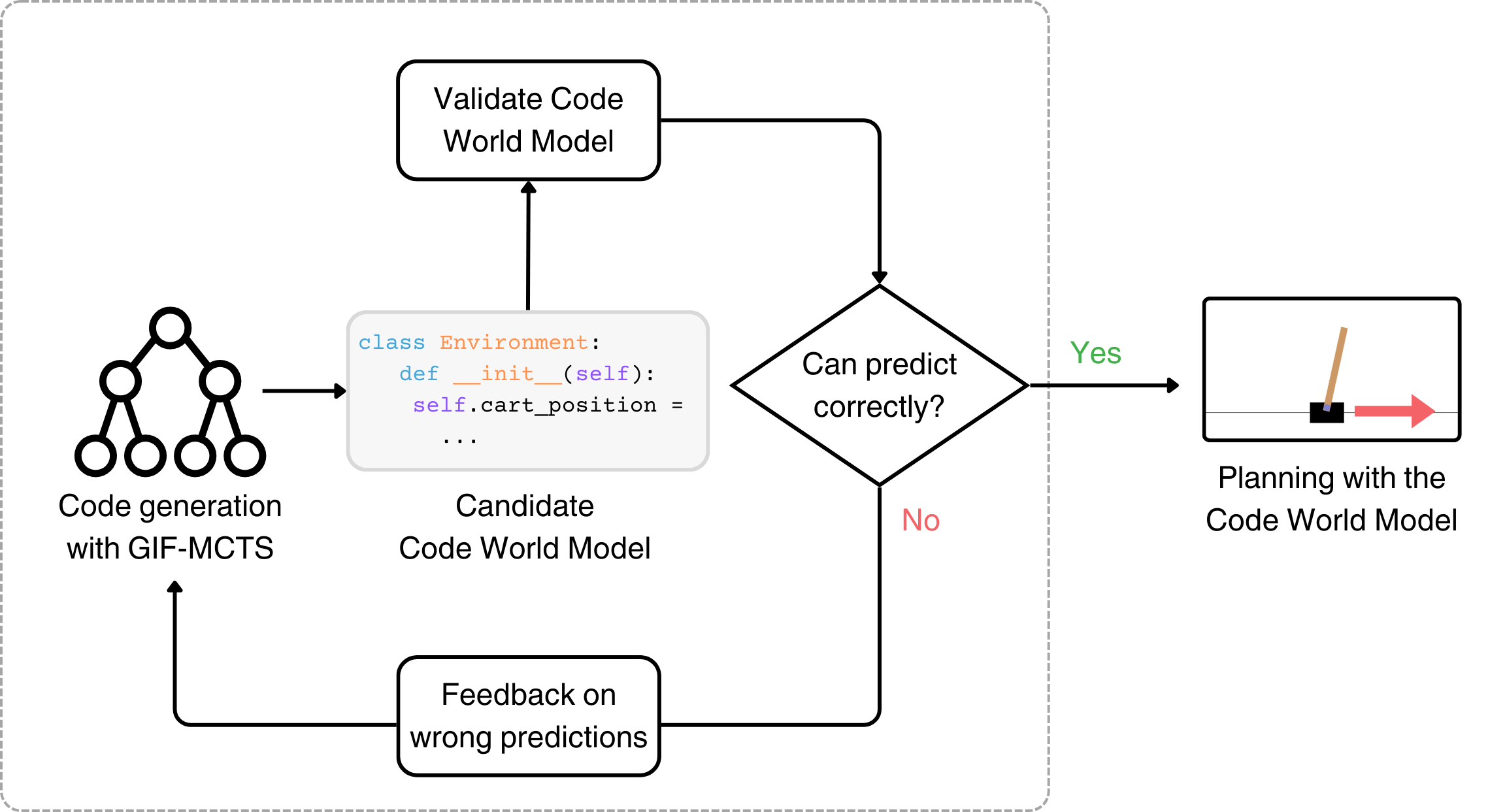
In this work we consider Code World Models, world models generated by a Large Language Model (LLM) in the form of Python code for model-based Reinforcement Learning (RL). Calling code instead of LLMs for planning has potential to be more precise, reliable, interpretable, and extremely efficient. However, writing appropriate Code World Models requires the ability to understand complex instructions, to generate exact code with non-trivial logic and to self-debug a long program with feedback from unit tests and environment trajectories. To address these challenges, we propose Generate, Improve and Fix with Monte Carlo Tree Search (GIF-MCTS), a new code generation strategy for LLMs. To test our approach in an offline RL setting, we introduce the Code World Models Benchmark (CWMB), a suite of program synthesis and planning tasks comprised of 18 diverse RL environments paired with corresponding textual descriptions and curated trajectories. GIF-MCTS surpasses all baselines on the CWMB and two other benchmarks, and we show that the Code World Models synthesized with it can be successfully used for planning, resulting in model-based RL agents with greatly improved sample efficiency and inference speed.
@inproceedings{dainese2024generating,author={Dainese, Nicola and Merler, Matteo and Alakuijala, Minttu and Marttinen, Pekka},booktitle={Advances in Neural Information Processing Systems},editor={Globerson, A. and Mackey, L. and Belgrave, D. and Fan, A. and Paquet, U. and Tomczak, J. and Zhang, C.},pages={60429--60474},publisher={Curran Associates, Inc.},title={Generating Code World Models with Large Language Models Guided by Monte Carlo Tree Search},url={https://proceedings.neurips.cc/paper_files/paper/2024/hash/6f479ea488e0908ac8b1b37b27fd134c-Abstract-Conference.html},volume={37},year={2024},cv_venue={Advances in Neural Information Processing Systems 37 (NeurIPS 2024)},cv_date={2024-12-13},}